Building only what matters for a schema-less data source.
Integrating with MongoDB
During the 2023-2024 period, while at Hasura, I had the unique opportunity to wear multiple hats.
As the Design Director, I was already deeply involved in shaping our product's user and developer experience.
However, when our product team found itself short-staffed, I stepped up to take on an additional role as the interim product owner for NoSQL data sources, with a specific focus on MongoDB integration.
The Challenge
Our mission was clear: to extend Hasura's powerful GraphQL API generation capabilities to NoSQL databases, specifically MongoDB.
This presented a fascinating challenge, as it required us to bridge the gap between Hasura's structured approach and MongoDB's schema-less nature.
Initial Research and Discovery
We kicked off the project with a deep dive into user needs:
We tapped into our waitlist for NoSQL support, which was pretty substantial.
We engaged with a large existing client who had a significant MongoDB deployment and was interested in adding it to their graph.
We did a bunch of market research to look at what prior art in the MongoDB + GraphQL / API market looked like, as well as the pain-points of creating an API using MongoDB.
We had a bunch of progress reports, call-outs, and requests for comments as we worked through the integration.
We worked with MongoDB's developer relations team to get an idea about what they were seeing on their side in the API / GraphQL market and if there was a possibility for a partnership.
Our research quickly revealed that users were excited about Hasura's core features:
Robust permissions management.
The ability to join data across different sources.
Auto-generated boilerplate API from database objects.
Push-downs for all of this query logic to the database (something not all ORMs did performantly).
However, we encountered a unique challenge with MongoDB: its schema-less nature.
To leverage Hasura's strengths, we needed to find a way to impose some form of typing on the data.
The Decision: Query-Level vs. Collection-Level Typing
We faced a critical decision point: should we implement typing at the query level or the collection level?
After extensive customer interviews, we discovered:
Most users already had some structure around their collection-level documents, often managed through ORMs.
The prospect of a one-click setup for collection-based APIs was highly appealing to our users.
Query-level typing, while useful, was seen as less critical for the initial release.
This insight guided our decision to focus on collection-level typing for our V1 release, with plans to add query-level flexibility in future iterations.
We also figured out that if we were able to work this out, there would be a huge benefit - we'd be the de-facto source of truth for the structure of the NoSQL collections.
The Schema Inference Challenge
With our direction set, we needed to tackle the next hurdle: how to generate a schema for collections without a predefined structure.
We considered various options:
Integrating with popular ORMs (ruled out due to lack of standardization).
Using MongoDB's built-in validation schema (limited adoption among users - albeit easier for us to implement since it had a similar model to our other data sources).
Some form of schema inference system dependent on the records in the collection.
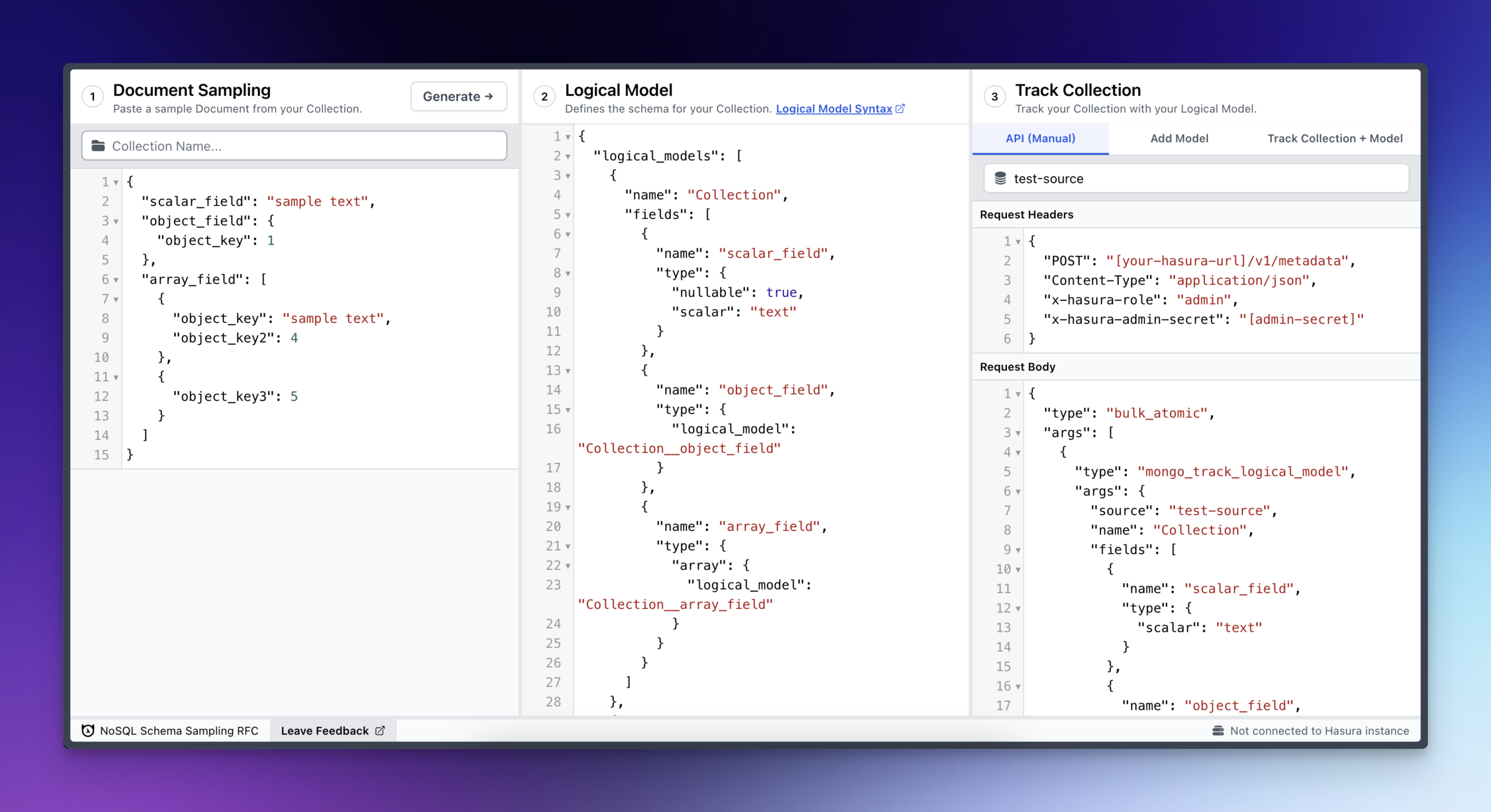
Our final solution? Develop a schema inference system based on document sampling.
It struck the best balance between developer experience and breadth of users who could benefit from the feature.
The downside was that it took a bit more effort to implement, so we wanted to make sure the approach was sound.
Validating Our Approach
Introduction to MongoDB + NoSQL at Hasura, and a request for comments.
To ensure we were on the right track, we implemented a multi-step validation process:
We drafted a detailed RFC (request for comments) outlining our proposal.
You can have a look at our writeup of the RFC for the feature over here.
We developed a proof-of-concept (POC) tool that simulated our proposed feature.
We actually developed 2 proof of concepts:
One which demonstrated how the schemas would be extracted.
Another which demonstrated inputting the types back into a demo Hasura instance.
We shared this POC with our large enterprise customer and our sales engineering team (for other engagements) for real-world testing and feedback.
Screenshot of the MongoDB POC "tool" which I built out to gather feedback on the solution, and give the sales engineering team a useful bandaid which they could use to demo in meetings with stakeholders to collect feedback.
Minimum Viable Product (MVP)
Encouraged by positive feedback, we moved forward with an MVP:
We adapted our POC into a functional interface within our V2 application.
This allowed us to gather additional user insights while our V3 product was still in beta to ensure the path we were going down was solid before baking it into the server-side.
Our 1.0 "general availability" launch for V2, used for gathering more functional feedback.
Final Implementation and Launch
Armed with a wealth of user feedback and proof points, we proceeded with the full implementation where we integrated the feature into the server-side of our V3-stable product (a larger integration).
The feature was successfully launched in July 2024 (a couple of months after I had left the company), marking a significant milestone in Hasura's NoSQL support capabilities.