At Hasura, we faced a critical challenge in new user engagement.
Our data revealed a concerning trend: many users had fewer than five tables in their managed, Cloud-hosted projects.
This wasn't particularly surprising because our ideal customer profile (ICP) consisted of larger customers who bring their own data.
However, we couldn't ignore the importance of these independent developers, checking out the platform for their first-time experience.
The bottom-up approach had been crucial for our growth.
Converting these new users into active users was vital for our long-term success.
Demonstrating to them development experience and velocity we could provide could help them become advocates within their organizations.
We dove deep into the user experience, determined to uncover the secret sauce that would make Hasura's potential crystal clear to newcomers.
After some brain-storming and data crunching, we identified four key ingredients for our perfect onboarding recipe:
These elements weren't just checkboxes - they were the building blocks of the "aha!" moment we wanted every user to experience.
By combining these components, we aimed to create a powerful first impression that would leave users eager to explore more, or reach for Hasura in their next project.
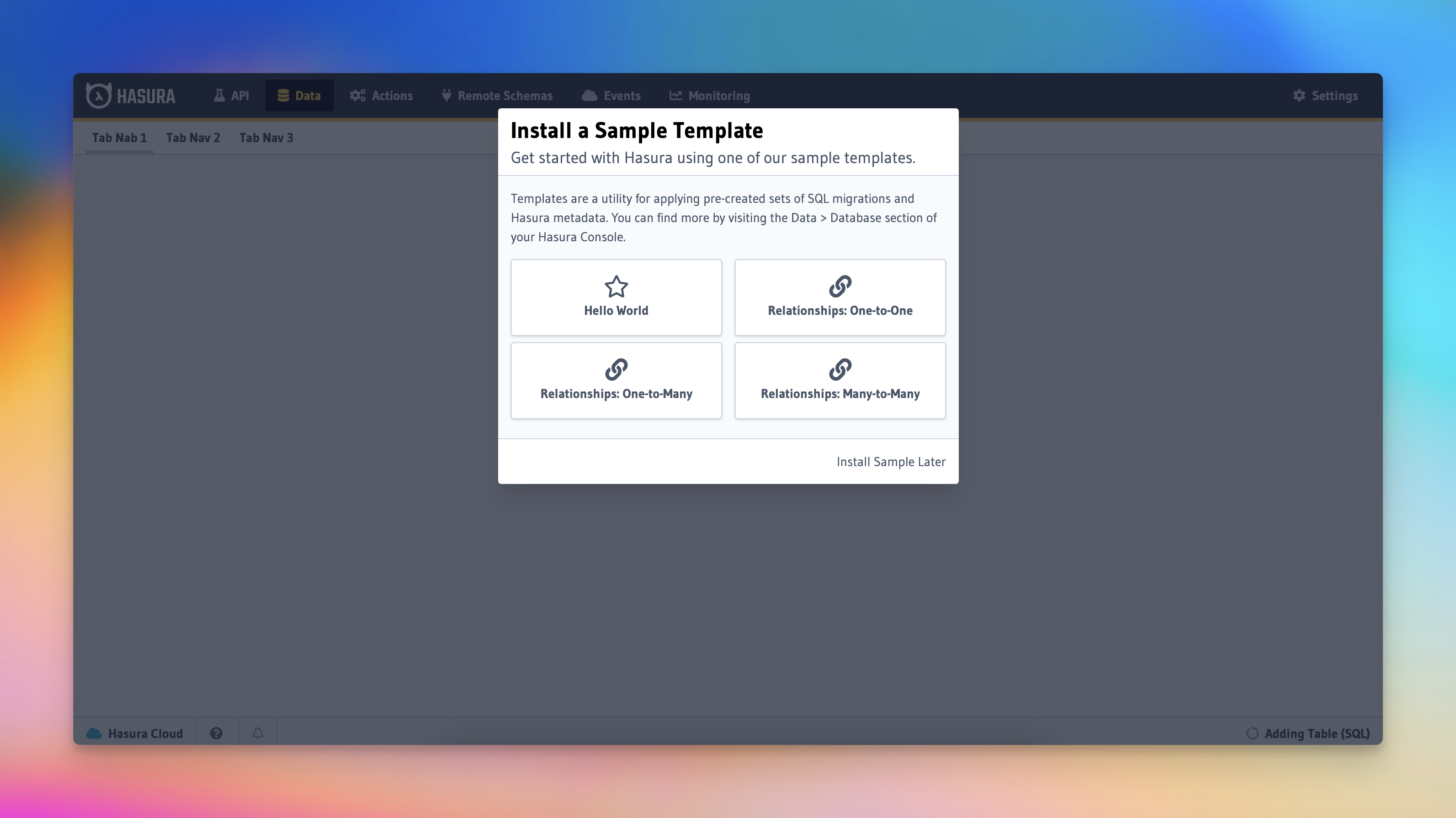
Armed with our insights, we crafted a solution: a turbocharged quick-start path the user could take.
Here's how it works:
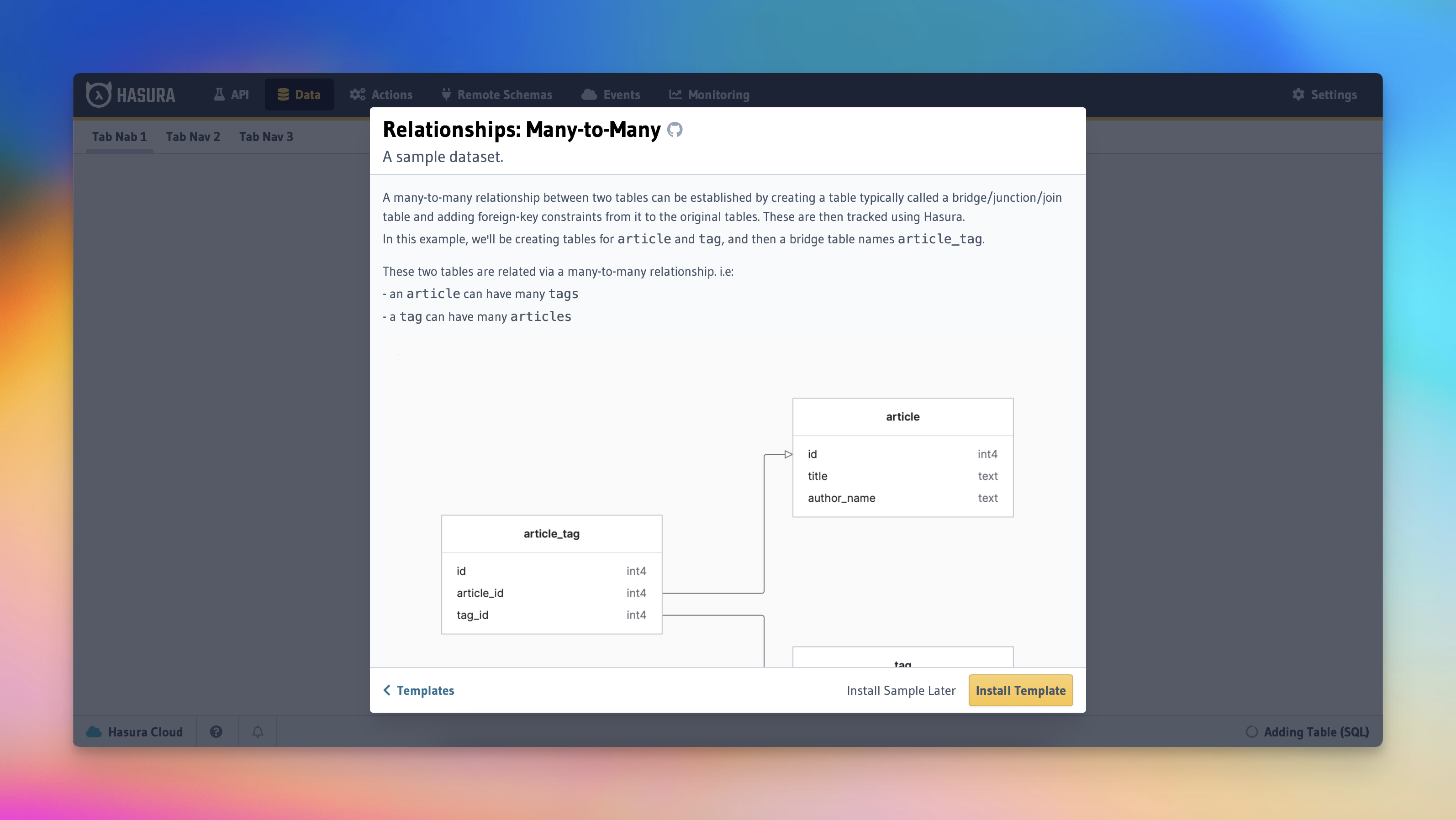
The result? A fully functional Hasura platform, ready to roll with an example "feature" implemented for the user.
This wasn't just a time-saver; it was a quite the leap ahead for user onboarding.
What typically took hours coding for developers to setup without Hasura for was now accomplished in seconds.
Users could instantly experience a working "feature," complete with sample data and the bells and whistles of Hasura's capabilities.
It was like handing users the keys to a fully-furnished house instead of an empty lot.
They could walk in and immediately start exploring the possibilities - no construction required.
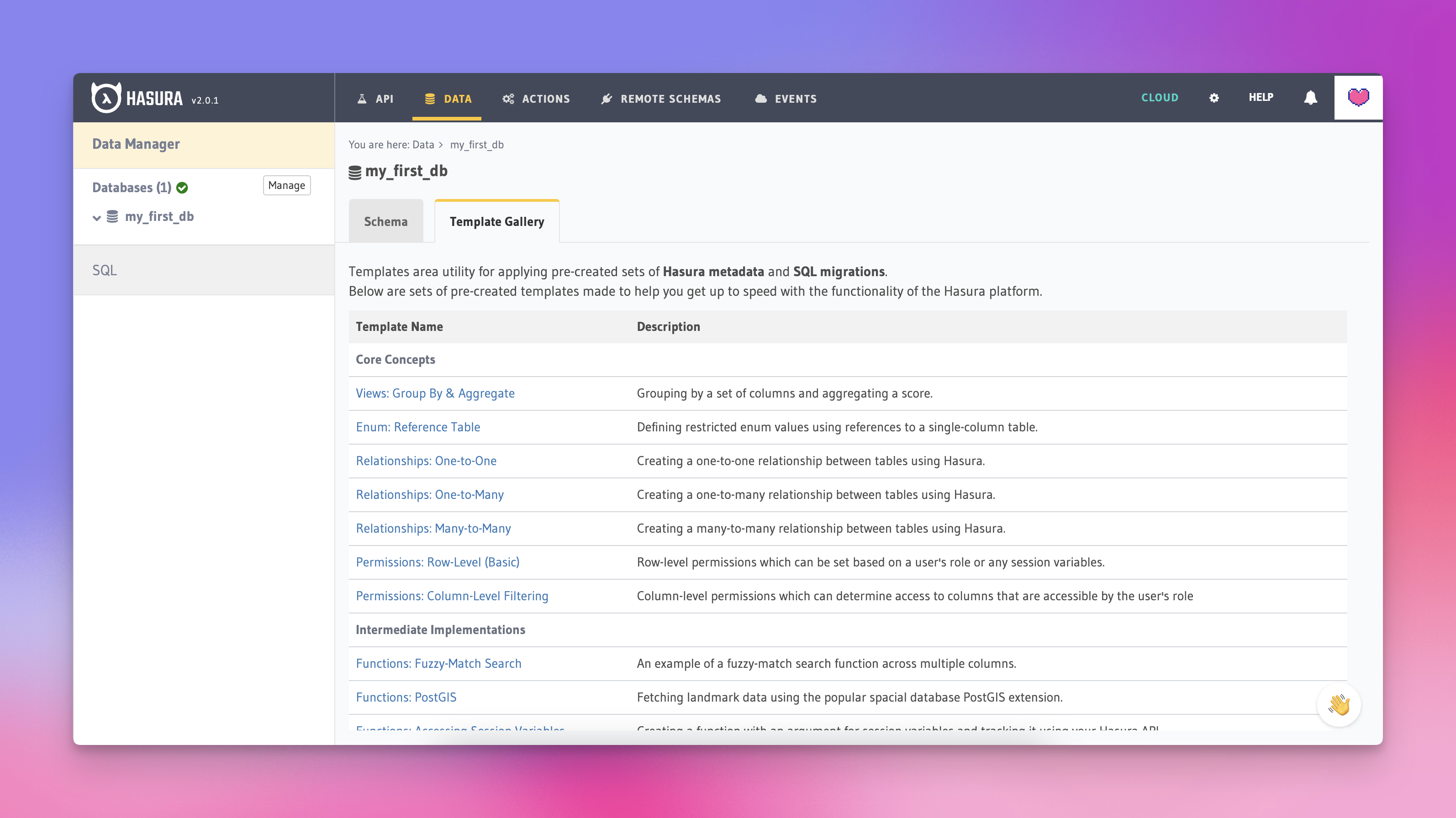
You can check out the initial templates we created over on the project's GitHub page.
We launched the first version of this feature at HasuraCon.
The reception was positive, with decent traction at launch.
It successfully helped demonstrate Hasura's ecosystem to new users and facilitated the onboarding process.
Looking ahead, we envisioned creating an ecosystem of small, installable applets for new users.
We also saw potential for teams to use this method for sharing snippets or packages within their organizations.
Despite its initial success, the feature faced some hurdles over time:
Technical limitations:
ICP misalignment:
Due to these challenges, we eventually decided to deprecate the feature.
The learnings from this project weren't in vain though:
Deploy from GitHub.